1. 简介
我们在运行Spark任务的时候,通过hadoop1:4040可以查看到当前的运行状态,包括各节点的任务量,完成的任务量等,可是当任务结束后,就访问不到这些信息了。本文将配置spark的运行日志,使得可以在任务结束后,依然可以查看到该任务执行过程中的各项系数。这不仅可以使我们对spark系统有更深入的了解,还可以便于我们查找程序问题,调试程序。
2. 配置
2.1 spark-default.conf
在spark安装目录下的conf目录下,将spark-default.conf.template 改名为 spark-default.conf,并添加如下内容:
spark.eventLog.enabled true
spark.eventLog.dir file:/home/hadoop/log/spark[hdfs://hadoop1:9000/log/spark]
spark.eventLog.compress true
spark.eventLog.dir
默认值:file://tmp/spark-events
保存日志相关信息的路径,可以是hdfs://开头的HDFS路径,也可以是file://开头的本地路径,但都需要提前创建目录。
2.2 spark-env.sh
添加如下内容:
Export SPARK_HISTORY_OPTS=-Dspark.history.fs.logDirectory=hadoop1:9000/log/spark -Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3
spark.history.retainedApplications
默认值:50
在内存中保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,当再次访问已被删除的应用信息时需要重新构建页面。
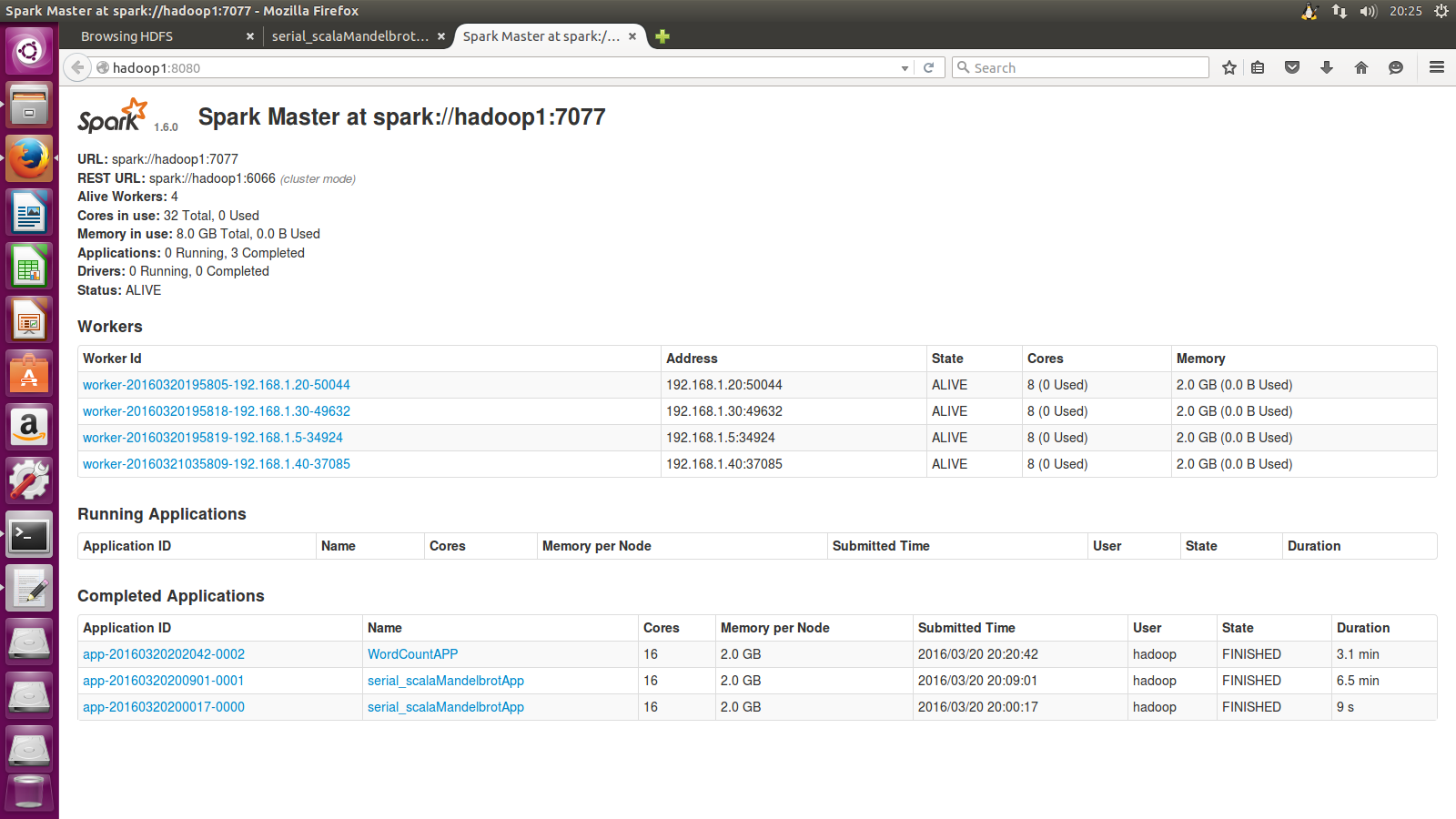
3. 启动
SPARK_HOME/conf下:执行./start-history-server.sh,以后执行sbin/start-all.sh就可以了。
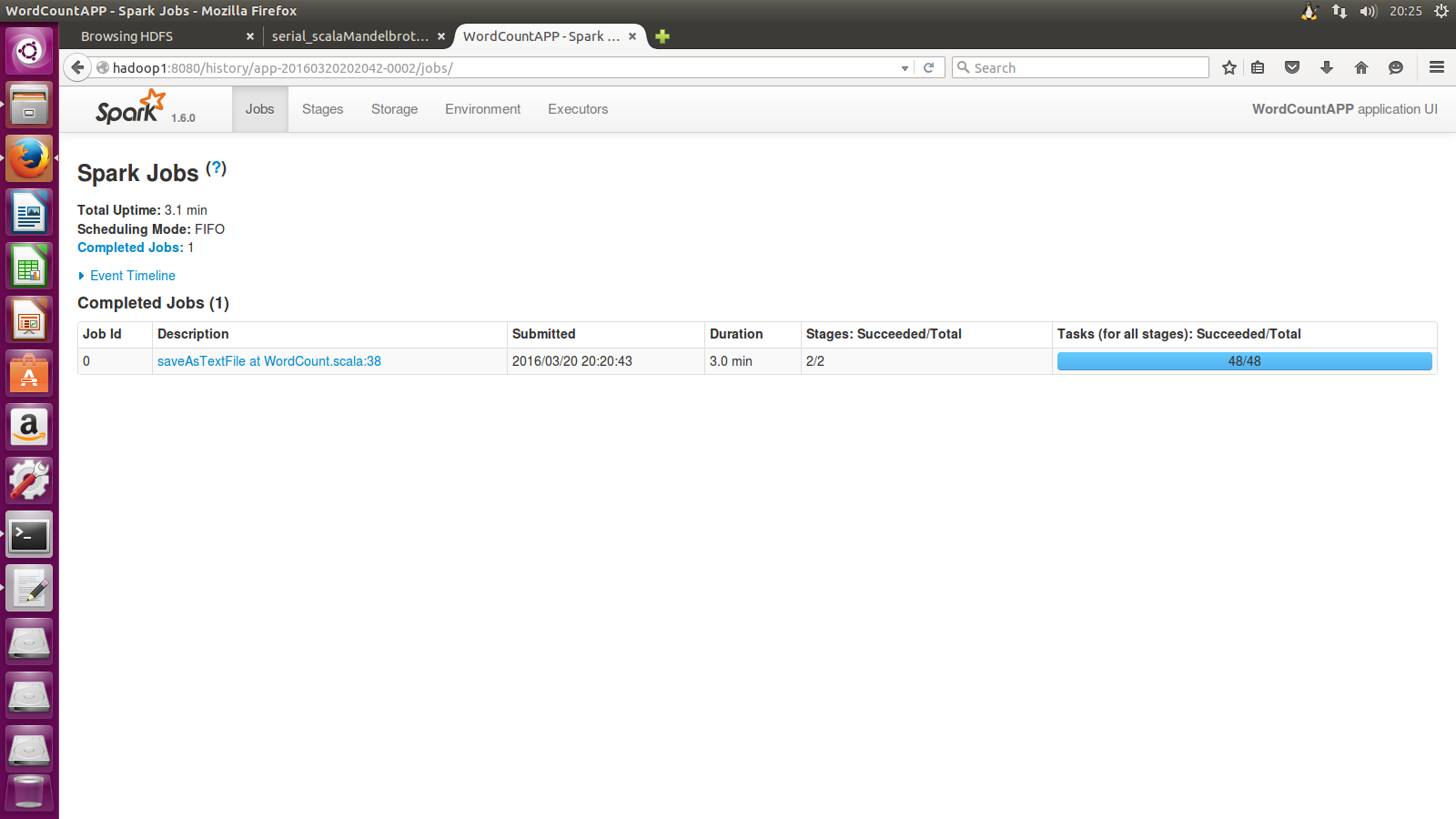
4. 演示
执行一个wordcount实例后产生的日志
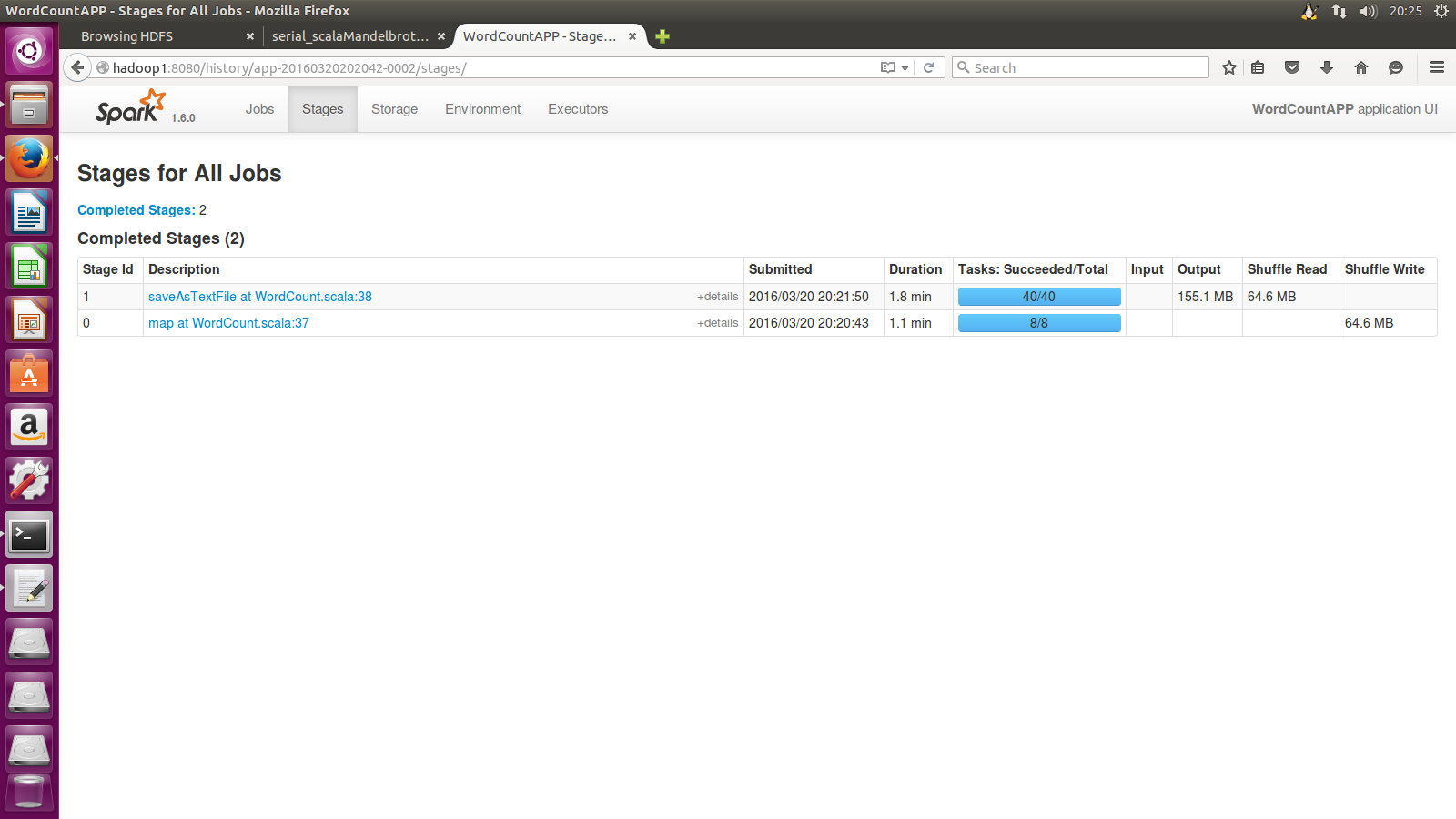
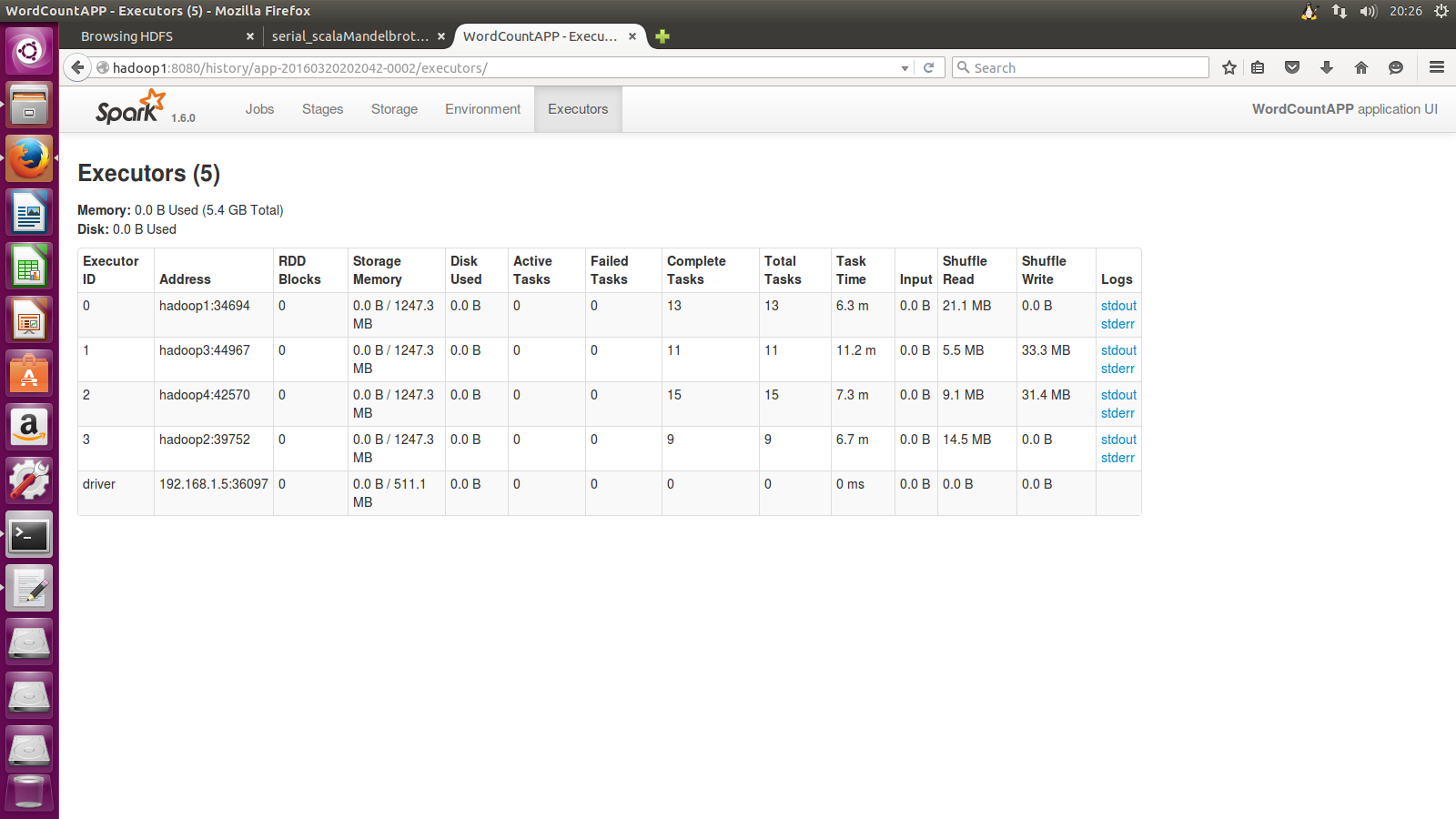
点击应用名字WordCountAPP后即可查看各项情况