1. 运行环境
本文搭建的是Spark Standalone模式,在已搭建好的Hadoop2.6.4集群上部署Spark。
版本信息:
- JDK:1.8.0_74 64位
- Hadoop:2.6.4
- Spark:1.6.0
- Scala:2.12.0-M3
2. 下载Spark
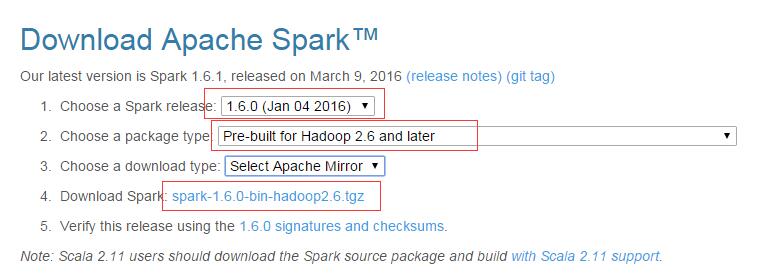
3. 安装Scala
3.1 解压缩
sudo mkdir /home/hadoop/scala
sudo tar -zxf scala-2.12.0-M3.tgz -C /home/hadoop/scala
3.2 修改环境变量
sudo vim ~/.bashrc
SCALA_HOME=/home/hadoop/scala/scala-2.12.0-M3
export PATH=$HADOOP_HOME/bin:$SCALA_HOME/bin:$JAVA_HOME/bin:$JRE_HOME/bin:$JAVA_HOME:$PATH
3.3 使配置文件生效
source ~/.bashrc
3.4 显示版本及测试
scala -version
scala
5*5
:q or CTRL+D
4. 分发scala到各从节点
scp -r /home/hadoop/scala hadoop@hadoop2:/home/hadoop/
scp -r /home/hadoop/.bashrc hadoop@hadoop2:/home/hadoop/
5. 安装Spark
5.1 解压缩
sudo tar -zxf spark-1.6.0-bin-hadoop2.6.tgz -C /home/hadoop/
5.2 配置环境变量
sudo vim ~/.bashrc
export SPARK_HOME=/home/hadoop/spark-1.6-bin-hadoop2.6
export PATH=$SPARK_HOME/bin:$HADOOP_HOME/bin:$SCALA_HOME/bin:$JAVA_HOME/bin:$JRE_HOME/bin:$JAVA_HOME:$PATH
5.3 使配置生效
source ~/.bashrc
5.4 spark-env.sh
进入spark目录下的conf目录,将spark-env.sh.template拷贝到spark-env.sh,并添加信息:
cp spark-env.sh.template spark-env.sh
export JAVA_HOME=/home/hadoop/java/jdk1.8.0_74
export SCALA_HOME=/home/hadoop/scala/scala-2.12.0-M3
export SPARK_MASTER_IP=hadoop1
export SPARK_WORKER_MEMORY=2g
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.6.4/conf
5.5 slavers
在slavers文件中添加各个从节点hadoop2,hadoop3…
6. 分发spark到各个从节点
scp -r /home/hadoop/spark-1.6.0-bin-hadoop2.6 hadoop@hadoop2:/home/hadoop/
scp -r ~/.bashrc hadoop@hadoop2:~/
7. 启动集群
7.1 启动HDFS
sbin/start-dfs.sh
7.2 启动spark
sbin/start-all.sh
7.3 新进程
使用jps命令之后,hadoop1主节点出现Master进程,其他从节点出现Worker进程
7.4 Spark UI
http://hadoop1:8080
7.5 Spark-Shell
bin/spark-shell
8. 测试
8.1 spark-shell命令行下wordcount测试
1. spark-shell
2. val file = sc.textFile("hdfs://hadoop1:9000/input/")
3. val count = file.flatMap(line=>(line.split(" "))).map(word=>(word,1)).reduceByKey(_+_)
4. count.collect()
5. count.saveAsTextFile("hdfs://hadoop1:9000/output/wordcount")
8.2 jar包测试
bin/spark-submit --class WordCount.WordCount --master spark://hadoop1:7077 ~/data/WordCount.jar hdfs://hadoop1:9000/input/ hdfs://hadoop1:9000/output/